Acceptance and rejection method
acceptance_rejection.RmdUnderstanding the Method
In situations where we cannot use the inversion method (situations where obtaining the quantile function is not possible) and neither do we know a transformation involving a random variable from which we can generate observations, we can make use of the acceptance-rejection method.
Suppose \(X\) and \(Y\) are random variables with probability density function (pdf) or probability function (pf) \(f\) and \(g\), respectively. Furthermore, suppose there exists a constant \(c\) such that
\[\frac{f(t)}{g(t)} \leq c,\] for every value of \(t\), with \(f(t) > 0\). To use the acceptance-rejection method to generate observations of the random variable \(X\), using the algorithm below, first find a random variable \(Y\) with pdf or pf \(g\), such that it satisfies the above condition.
Important:
It is important that the chosen random variable \(Y\) is such that you can easily generate its observations. This is because the acceptance-rejection method is computationally more intensive than more direct methods such as the transformation method or the inversion method, which only requires the generation of pseudo-random numbers with a uniform distribution.
Algorithm of the Acceptance-Rejection Method:
1 - Generate an observation \(y\) from a random variable \(Y\) with pdf/pf \(g\);
2 - Generate an observation \(u\) from a random variable \(U\sim \mathcal{U} (0, 1)\);
3 - If \(u < \frac{f(y)}{cg(y)}\) accept \(x = y\); otherwise reject \(y\) as an observation of the random variable \(X\) and go back to step 1.
Proof: Consider the discrete case, that is, \(X\) and \(Y\) are random variables with pfs \(f\) and \(g\), respectively. By step 3 of the algorithm above, we have \(\{accept\} = \{x = y\} = u < \frac{f(y)}{cg(y)}\). That is,
\[P(accept | Y = y) = \frac{P(accept \cap \{Y = y\})}{g(y)} = \frac{P(U \leq f(y)/cg(y)) \times g(y)}{g(y)} = \frac{f(y)}{cg(y)}.\] Hence, by the Law of Total Probability, we have:
\[P(accept) = \sum_y P(accept|Y=y)\times P(Y=y) = \sum_y \frac{f(y)}{cg(y)}\times g(y) = \frac{1}{c}.\] Therefore, by the acceptance-rejection method, we accept the occurrence of \(Y\) as an occurrence of \(X\) with probability \(1/c\). Moreover, by Bayes’ Theorem, we have
\[P(Y = y | accept) = \frac{P(accept|Y = y)\times g(y)}{P(accept)} = \frac{[f(y)/cg(y)] \times g(y)}{1/c} = f(y).\] The result above shows that accepting \(x = y\) by the algorithm’s procedure is equivalent to accepting a value from \(X\) that has pf \(f\). For the continuous case, the proof is similar.
Important:
Notice that to reduce the computational cost of the method, we should choose \(c\) in such a way that we can maximize \(P(accept)\). Therefore, choosing an excessively large value of the constant \(c\) will reduce the probability of accepting an observation from \(Y\) as an observation of the random variable \(X\).
Note:
Computationally, it is convenient to consider \(Y\) as a random variable with a uniform distribution on the support of \(f\), since generating observations from a uniform distribution is straightforward on any computer. For the discrete case, considering \(Y\) with a discrete uniform distribution might be a good alternative.
Installation and loading the package
The zmpg package is available on CRAN and can be
installed using the following command:
# install.packages("remotes")
remotes::install_github("prdm0/zmpg", force = TRUE)
library(zmpg)Using the acceptance_rejection Function
Among various functions provided by the zmpg library, the
acceptance_rejection function implements the acceptance-rejection
method. The zmpg::acceptance_rejection() function has the
following signature:
acceptance_rejection(
n = 1L,
continuous = TRUE,
f = dweibull,
args_pdf = list(shape = 1, scale = 1),
xlim = c(0, 100),
c = NULL,
linesearch_algorithm = "LBFGS_LINESEARCH_BACKTRACKING_ARMIJO",
max_iterations = 1000L,
epsilon = 1e-06,
start_c = 25,
parallel = FALSE,
...
)Many of the arguments the user will not need to change, as the
zmpg::acceptance_rejection() function already has default
values for them. However, it is important to note that the f argument is
the probability density function (pdf) or probability function (pf) of
the random variable \(X\) from which
observations are desired to be generated. The args_pdf argument is a
list of arguments that will be passed to the f function. The
c argument is the value of the constant c that
will be used in the acceptance-rejection method. If the user does not
provide a value for c, the
zmpg::acceptance_rejection() function will calculate the
value of c that maximizes the probability of accepting
observations from \(Y\) as observations
from \(X\).
Note:
zmpg::acceptance_rejection() function can work in a
parallelized manner on Unix-based operating systems. If you use
operating systems such as Linux or MacOS, you can benefit from
parallelization of the zmpg::acceptance_rejection()
function. To do this, simply set the parallel = TRUE
argument. In Windows, parallelization is not supported, and setting the
parallel = TRUE argument will have no effect.
You do not need to define the c argument when using the
zmpg::acceptance_rejection() function. By default, if
c = NULL, the zmpg::acceptance_rejection()
function will calculate the value of c that maximizes the
probability of accepting observations from \(Y\) as observations from \(X\). However, if you want to set a value
for c, simply pass a value to the c
argument.
Details of the optimization of c:
c can be a
difficult optimization process, but generally, it is not. Therefore,
unless you have reasons to set a value for c, it is
recommended to use the default value c = NULL. For very
complicated functions, you may choose a sufficiently large
c to ensure that the method works well.
The arguments linesearch_algorithm,
max_iterations, epsilon, start_c,
and ... are arguments that control the optimization
algorithm of the c value. The
linesearch_algorithm argument is the line search algorithm
that will be used in the optimization of the c value. The
max_iterations argument is the maximum number of iterations
that the optimization algorithm will perform. The epsilon
argument is the stopping criterion of the optimization algorithm. The
start_c argument is the initial value of c
that will be used in the optimization algorithm. These are arguments
passed to the lbfgs::lbfgs() function, and generally, you
will not need to change them.
Examples
Below are some examples of using the
zmpg::acceptance_rejection() function to generate
pseudo-random observations of discrete and continuous random variables.
It should be noted that in the case of \(X\) being a discrete random variable, it is
necessary to provide the argument continuous = FALSE,
whereas in the case of \(X\) being
continuous (the default), you must consider
continuous = TRUE.
Generating discrete observations
As an example, let \(X \sim Poisson(\lambda
= 0.7)\). We will generate \(n =
1000\) observations of \(X\)
using the acceptance-rejection method, using the
zmpg::acceptance_rejection() function. Note that it is
necessary to provide the xlim argument. Try to set an upper
limit value for which the probability of \(X\) assuming that value is zero or very
close to zero. In this case, we choose xlim = c(0, 20),
where dpois(x = 20, lambda = 0.7) is very close to zero
(1.6286586^{-22}).
library(zmpg)
# Ensuring Reproducibility
set.seed(0)
# Generating observations
data <- zmpg::acceptance_rejection(
n = 1000L,
f = dpois,
continuous = FALSE,
args_pdf = list(lambda = 0.7),
xlim = c(0, 20),
parallel = TRUE
)
# Calculating the true probability function for each observed value
values <- unique(data)
true_prob <- dpois(values, lambda = 0.7)
# Calculating the observed probability for each value in the observations vector
obs_prob <- table(data) / length(data)
# Plotting the probabilities and observations
plot(values, true_prob, type = "p", pch = 16, col = "blue",
xlab = "x", ylab = "Probability", main = "Probability Function")
# Adding the observed probabilities
points(as.numeric(names(obs_prob)), obs_prob, pch = 16L, col = "red")
legend("topright", legend = c("True probability", "Observed probability"),
col = c("blue", "red"), pch = 16L, cex = 0.8)
grid()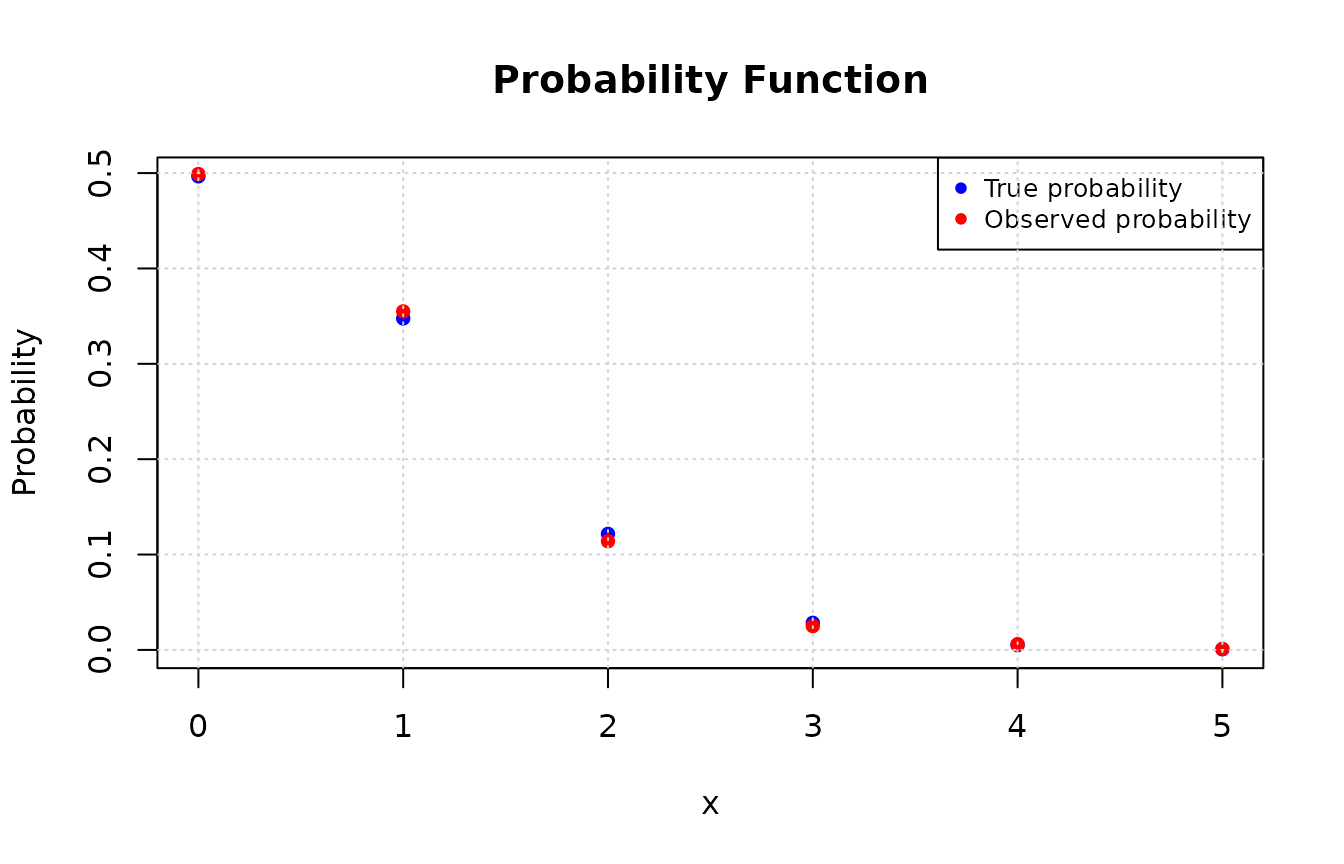
Note that it is necessary to specify the nature of the random
variable from which observations are desired to be generated. In the
case of discrete variables, the argument continuous = FALSE
must be passed.
Now, consider that we want to generate observations from a random variable \(X \sim Binomial(n = 5, p = 0.7)\). Below, we will generate \(n = 2000\) observations of \(X\).
library(zmpg)
# Ensuring reproducibility
set.seed(0)
# Generating observations
data <- zmpg::acceptance_rejection(
n = 2000L,
f = dbinom,
continuous = FALSE,
args_pdf = list(size = 5, prob = 0.5),
xlim = c(0, 20),
parallel = TRUE
)
# Calculating the true probability function for each observed value
values <- unique(data)
true_prob <- dbinom(values, size = 5, prob = 0.5)
# Calculating the observed probability for each value in the observations vector
obs_prob <- table(data) / length(data)
# Plotting the probabilities and observations
plot(values, true_prob, type = "p", pch = 16, col = "blue",
xlab = "x", ylab = "Probability", main = "Probability Function")
# Adding the observed probabilities
points(as.numeric(names(obs_prob)), obs_prob, pch = 16L, col = "red")
legend("topright", legend = c("True probability", "Observed probability"),
col = c("blue", "red"), pch = 16L, cex = 0.8)
grid()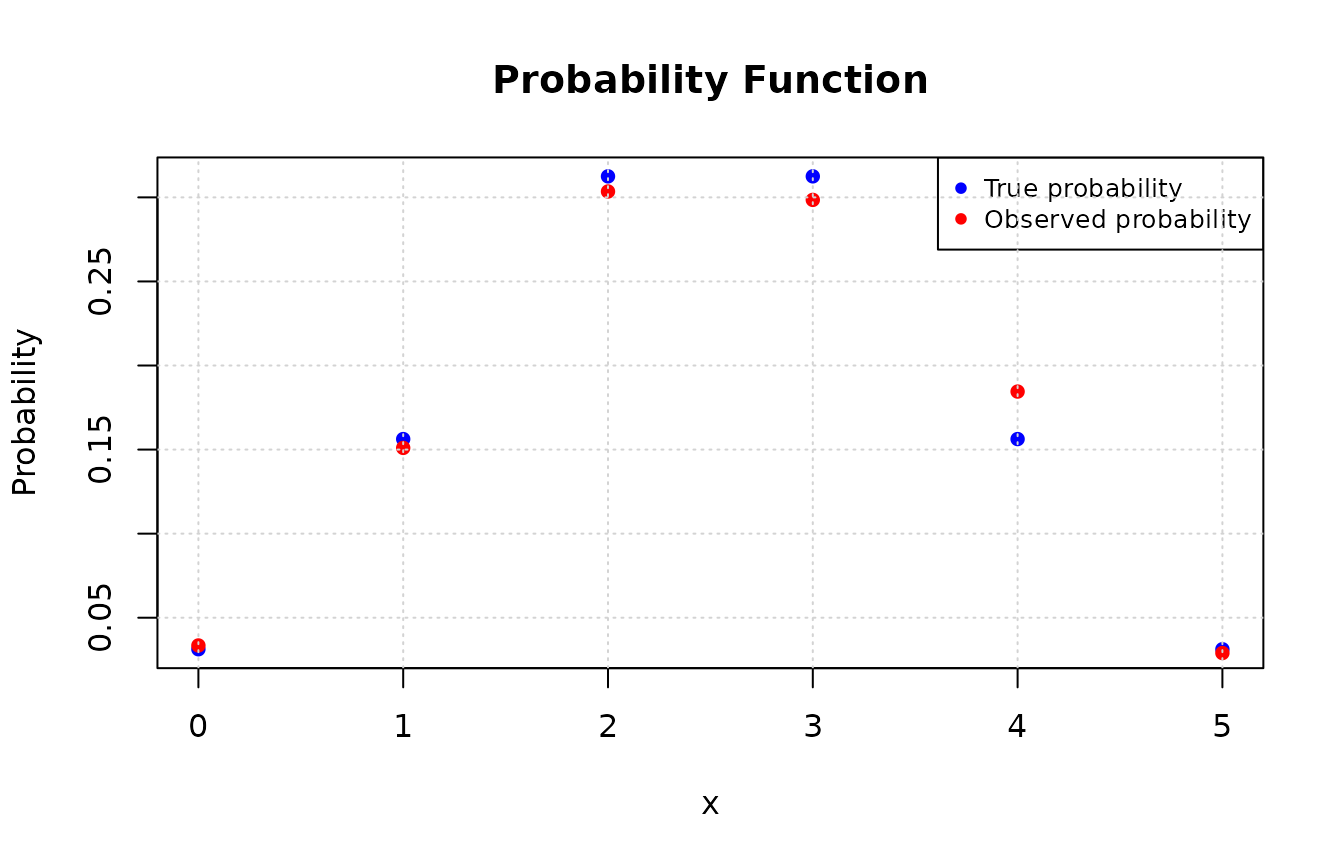
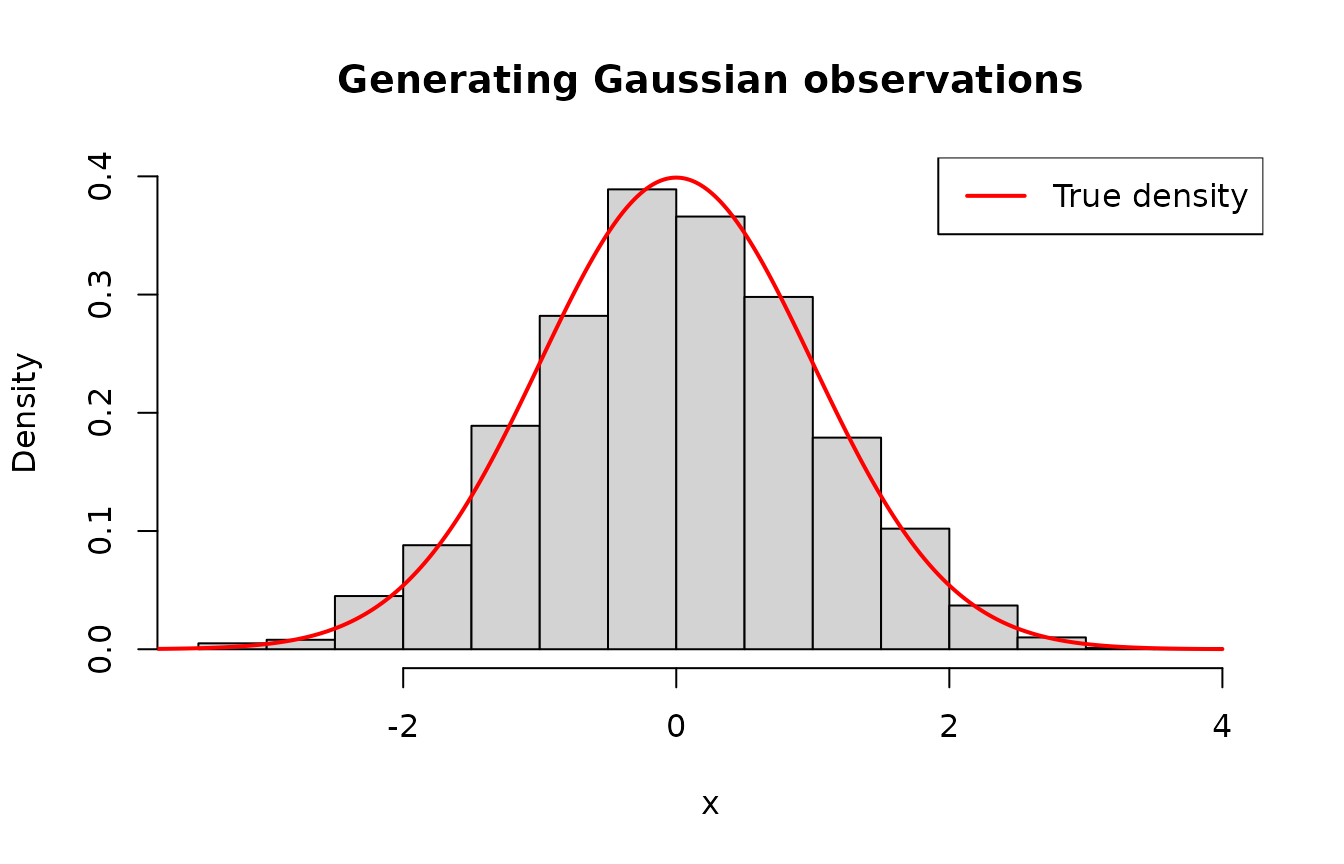
Generating continuous observations
To expand beyond examples of generating pseudo-random observations of
discrete random variables, consider now that we want to generate
observations from a random variable \(X \sim
\mathcal{N}(\mu = 0, \sigma^2 = 1)\). We chose the normal
distribution because we are familiar with its form, but you can choose
another distribution if desired. Below, we will generate
n = 2000 observations using the acceptance-rejection
method. Note that continuous = TRUE.
library(zmpg)
# Ensuring reproducibility
set.seed(0)
# Generating observations
data <- zmpg::acceptance_rejection(
n = 2000L,
f = dnorm,
continuous = TRUE,
args_pdf = list(mean = 0, sd = 1),
xlim = c(-4, 4),
parallel = TRUE
)
hist(
data,
main = "Generating Gaussian observations",
xlab = "x",
probability = TRUE,
ylim = c(0, 0.4)
)
x <- seq(-4, 4, length.out = 500L)
y <- dnorm(x, mean = 0, sd = 1)
lines(x, y, col = "red", lwd = 2)
legend("topright", legend = "True density", col = "red", lwd = 2)